機器學習練(一)【以Kaggle資料集預測Spotify上歌曲的人氣度】
機器學習練習(一)【以Kaggle資料集預測Spotify上歌曲的人氣度】
前言
嗨大家好,我目前是資料科學領域的新生,必須累積作品集以釐清課堂上所學習到的概念,也期待作品集在找工作時能派上用場。計畫是想要將經典機器學習的方法都產出一個相對應的作品:迴歸、分類、分群。希望能夠付諸實行。
**正文
**我這次選用的資料集是在Kaggle上面找到的:Spotify Dataset 1921–2020,在平台上也有高手們運用同樣資料集所進行的預測。
1.讀取檔案
2.決定特徵值與標籤值
3.處理缺失值
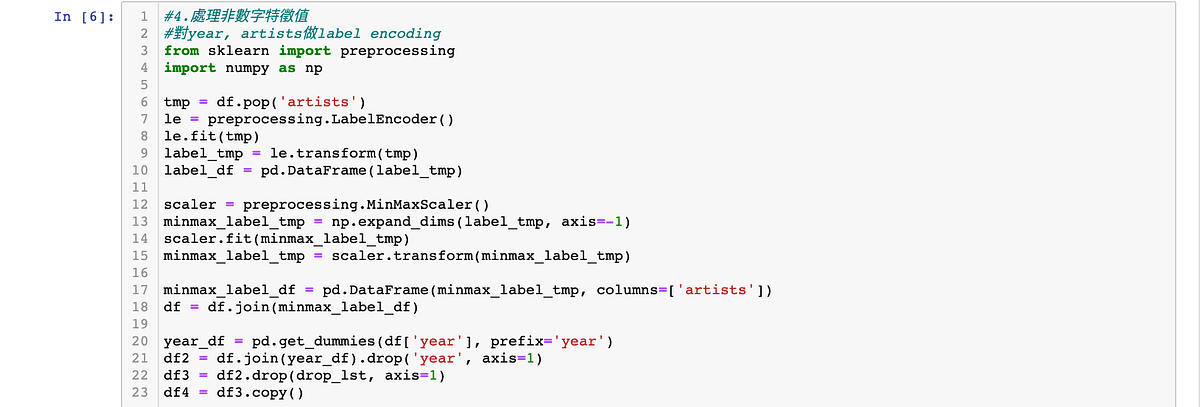
4.處理非數字特徵值
5.套用模型
6.模型評估
7.嘗試只使用相關係數較高的欄位作為特徵,並再次評估預測結果
8.嘗試套用特徵處理模型,並再次評估預測結果
9.結論
- 讀取檔案,觀察資料的欄位。
2. 把用不到的特徵值去掉。
3. 處理缺失值 4. 處理非數字特徵值。在課堂中幾乎每一位老師,都會再三強調實務上最花時間的步驟,就是在資料的預處理上,而Kaggle上的資料幾乎都非常地乾淨,因此在這兩個步驟上不需要做太多的事情。
我首先觀察有沒有缺失值,而在整個資料集中有缺失職的欄位是name,但因為我並沒有要選用這個欄位作為我們模型的特徵,因此也不需要處理缺失值。
在處理非數字特徵值時,需要處理的欄位有artists和year,因為year的數字變化較少(1921–2020),所以我選擇用one-hot-encoding處理,而artists因為種類較多,因此選擇用label-encoding處理,處理完之後再用MinMaxScaler做歸一化,增加模型的穩定性。
因為我在資料預處理上的知識還很淺,所以這個練習基本上是有樣學樣做的。
目前理解為了要讓資料可以匯入模型中,因此必須先做one-hot-encoding或label-encoding,讓非數字的資料轉換成數字,而因為資料的數值有時可能落差很多,因此做標準化、歸一化、正則化可以讓模型更加穩定。

5. 套用模型,選擇用LinearRegression、RandomForest與AdaBoost三種模型,另外我測試了在訓練集與測試集為何種比例下,測試集的預測分數表現最好,我們可以很清楚地用圖表看出test size = 0.01時,測試集的表現最佳。
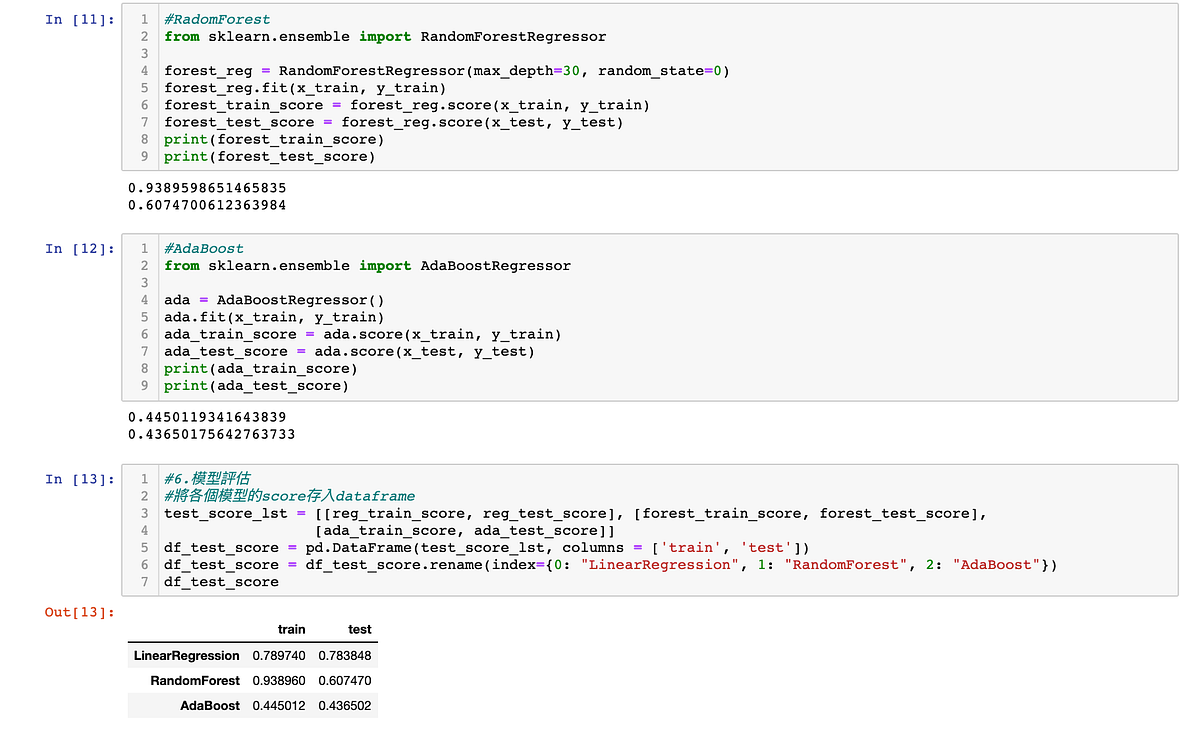
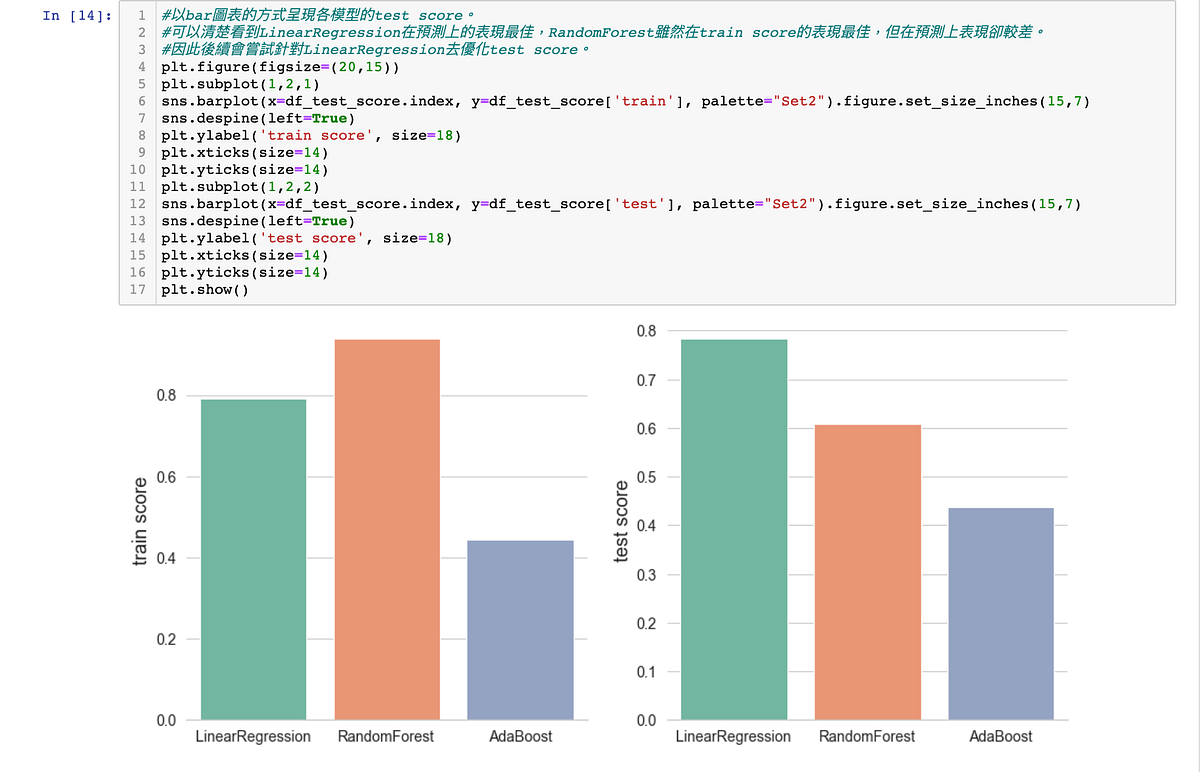
6. 模型評估,最後測試完三種模型後,再用圖表呈現彼此的預測分數,可以清楚看到LinerRegression在測試集的預測表現最好。



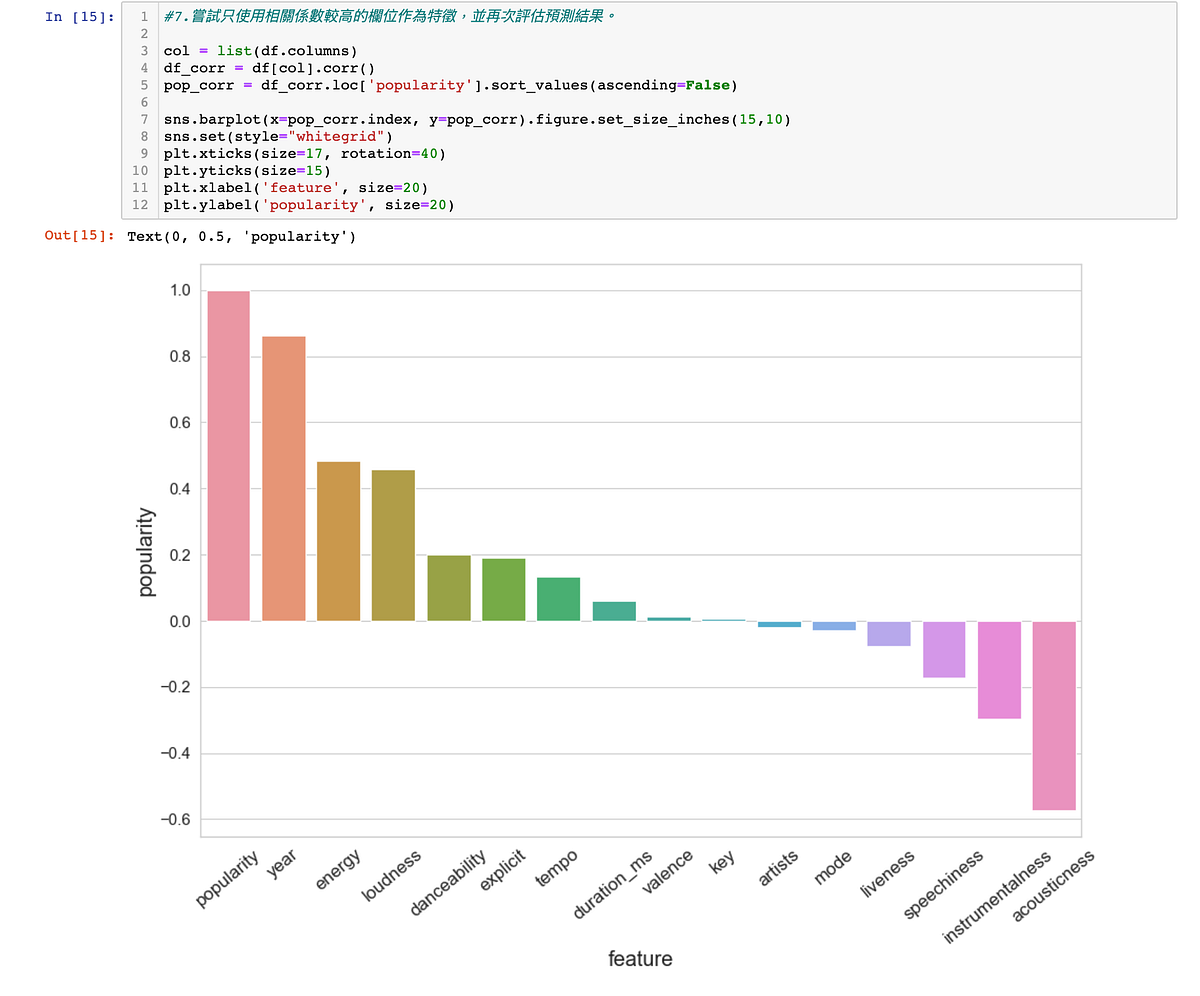
7. 接著我想嘗試只使用相關係數較高的欄位作為特徵,並再次評估預測結果。
因此先將相關係數高的欄位取出,我先定義相關係數高為:正相關大於第三個四分位數(>75%),或負相關小於中位數檢調一個標準差的值(<50% -std)。
接著套入LinearRegression觀察是否有比原本的模型表現更好,很可惜結果是差不多的,推測因為year與popularity的相關係數在這個資料集中太過突出,因此模型給予的權重較大,因此選取特徵時若將year選取進去,得到的預測分數就會差不多。


8.嘗試套用特徵處理模型,並再次評估預測結果。
因為自己選取的特徵並沒有讓模型表現得更好,因此想套用其他特徵處理模型,看能否優化模型。因此我上網快速瀏覽,選擇用了一個特徵處理模型:RFE,可惜結果也慘不忍睹。
最後我將透過這兩種特徵選取方式,所得到的模型分數給視覺化,可以看清楚地看出彼此間的關係。


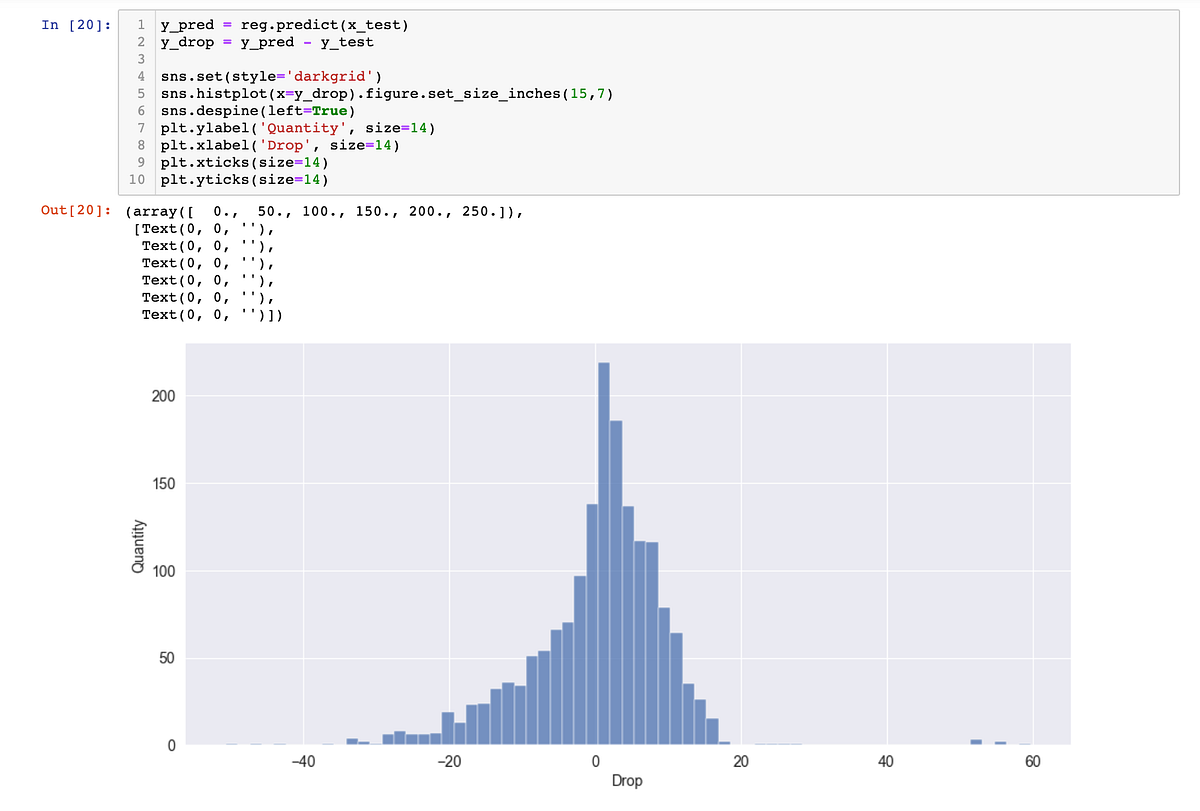
最後的最後,我將原本用LinearRegression模型所得到的預測資料(y_pred)與實際資料(y_test)相減,並用圖表呈現出預測與實際的落差,可以看到左半邊小於0的資料較多,也代表預測值比實際人氣度要小的失誤較多。
9.結論
1)在Spotify歌曲人氣度的預測上,以Linear Regression的預測效果較佳。
2)因year與popularity的相關性最高,目前模型也將year納入特徵中,但實務上我們並不能控制歌曲產生的年份,因此是否要將year納入特徵中,就仍有待討論。
未來優化方向
1)雖然嘗試透過特徵選取的方式,去優化模型在預測上的準確度,但目前所使用選取方式效果相當差,未來可以再嘗試套用其他種類的特徵選取模型。
2)可以透過polynomialfeatures將特徵的權重加重,以增加訓練資料的擬合度。
3)其他反饋,非常希望能有前輩能夠指點!!