【李宏毅老師2021系列】類神經網路訓練不起來怎麼辦 (五):批次標準化(Batch Normalization)簡介
【李宏毅老師2021系列】類神經網路訓練不起來怎麼辦 (五):批次標準化(Batch Normalization)簡介
這個系列是在觀看李宏毅老師2021系列的筆記,希望能用更濃縮的方式將內容整理下來。
前情提要
前面幾堂課,講了很多關於怎麼在 error surface 中找到 local minima,也就是找到一個 loss 相對小的 function。
我們也從前面的課程中,理解到在實務上要找到 local minima 不是件簡單的事情,因此這堂課要介紹的 Batch Normaliztion,也是一種為了讓模型更容易在訓練過程中尋找 loss 相對小的點,所使用的方式。
Changing Landscape: 把山剷平
前幾堂課發現,當 error surface 很崎嶇時,模型很難走到 loss 最小的那個地方,因此如果我們將 error surface 剷平,讓它不要那麼陡峭和崎嶇,訓練的過程就會比較容易,而 Batch Normalization 就是其中一種把山剷平的方法。
舉例來說,如圖1,當我們今天有兩個參數,w1 和 w2,當我們的 error surface 是一個碗的形狀時,就不見得很好訓練,因為 w1 對 loss 的斜率很小,w2 對 loss 的斜率很大。
因此如果用固定的 learning rate 去 optimize 參數,那麼就會很難走到圖中間 loss 小的區域,這也是為什麼需要前幾堂課介紹的 adaptive learning rate。
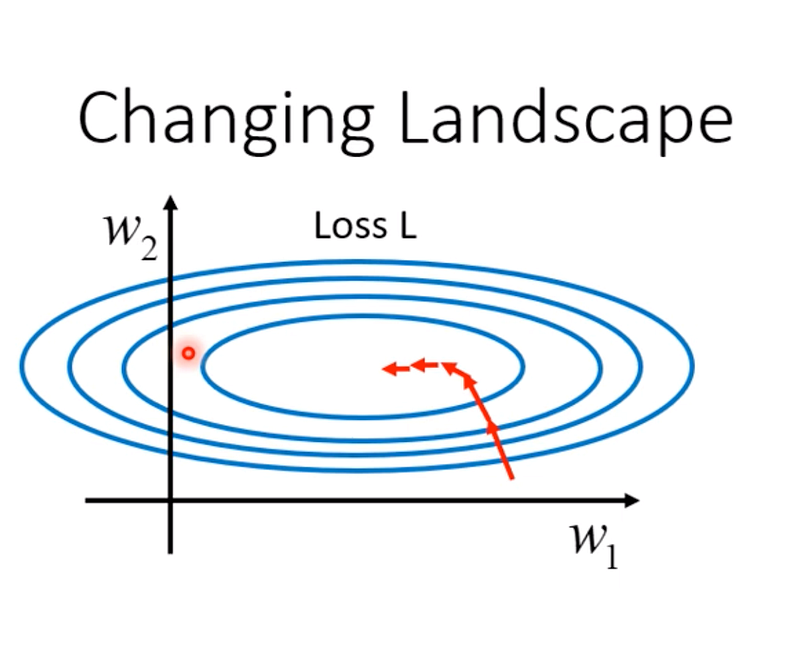
圖1 — 截圖自李宏毅老師課程
為何會產生這種 error surface?
延續上面的舉例,當我們今天有兩個 feature 是 x1, x2,它們的權重是 w1, w2,而且這是一個 linear 的模型,沒有 activation function,因此我們的 function 就會是 y = w1x1 + w2x2 + bias,而我們的 label 是 y hat,訓練過程就是去 minimize y 和 y hat 之間的差距。
因此我們會持續地更新 w1, w2,下圖更新的權重以 Δ 代表。
當今天 x1 的 input 很小的時候,Δw1 就算改變很大,對於 loss 也不會有太大的改變,當 x2 的 input 很大的時候,Δw2 就算只改變一點,對於 loss 就會有明顯的改變。
對於一個 linear 的模型來說,當輸入的 feature 之間的 scale 差距很大時,就會產生這樣的 error surface。
因此當我們將不同 dimension 的 feature 都調整到相同的範圍中,error surface 就會變成圖片右邊那樣,比較容易訓練。
聽到這邊也解答了我剛踏入資料科學就有的問題:為什麼要做 feature normalization?通常在網路上很常看到的解釋是,因為線性模型對於數字的 scale 比較敏感,因此做了 normalize 之後會比較好訓練,而樹模型就比較沒有這種問題。
雖然結論都是一樣的,但這堂課用清楚地用 error surface 說明了線性模型對於 feature scale 敏感性的問題。
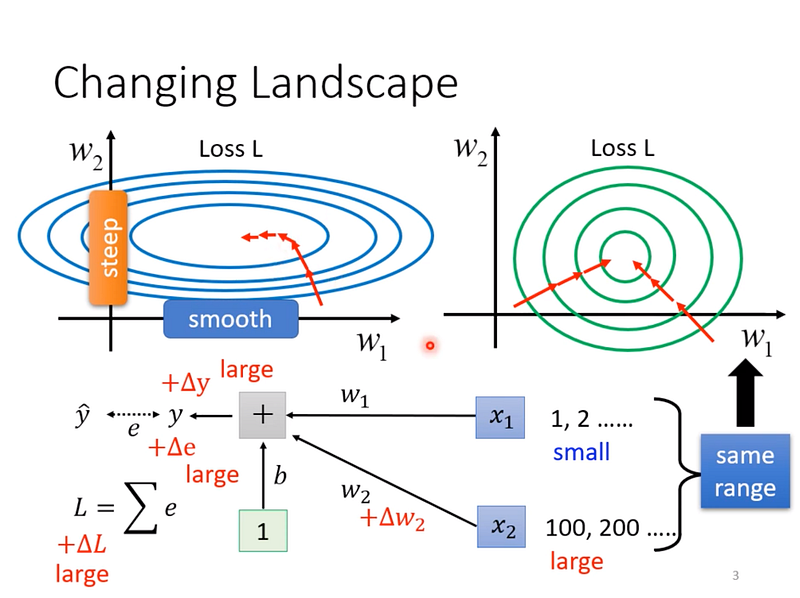
圖2 — 截圖自李宏毅老師課程
Feature Normalization
Feature normalization 網路上也有很多資源和公式,這邊介紹的其實是標準化,但老師說就統稱 normalization。
方式是當我們有一個 vector,裡面有 x1, x2, …, x10 個數值,我們就把這10個數值的平均值(mean)、標準差(standard deviation)算出來,將每個數值都帶入圖中的公式(xi 減去平均數再除以標準差),就會讓新的 vector 的平均數接近0,標準差為1。
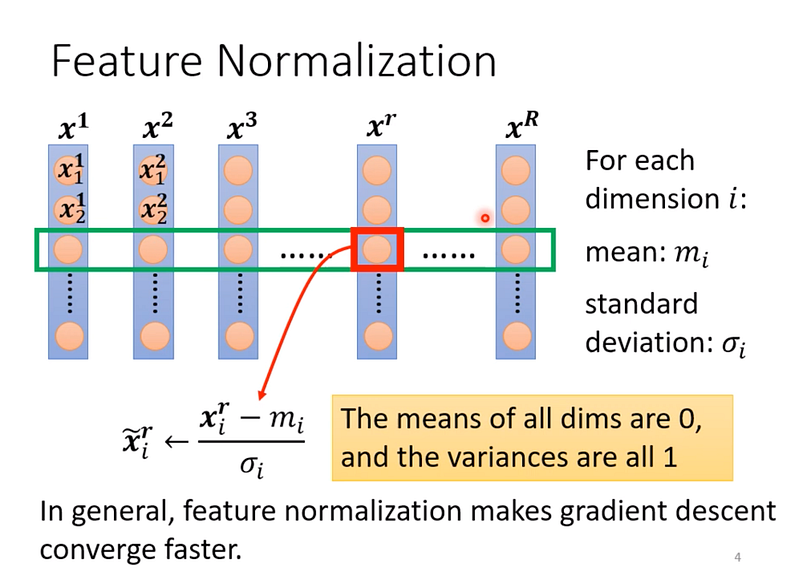
圖3— 截圖自李宏毅老師課程
Normalization in Deep Learning
當我們已經對 input 的 feature 做完 normalize 之後,把它們輸入進去模型,首先會先經過 w1 得到 z1,z1會再經過 activation function (這邊舉例用 sigmoid,它是一個s曲線的 activation function),得到 a1,然後才會進入下一層 layer。
雖然我們已經對 input 做完 normalize,但通過 w1後,得到的 z1 這組 vector 在不同維度上也有不同的 scale,就等於沒有做 normalize了,那麼我們要訓練 w2 可能就會很困難了,因此我們需要對 z1 做 normalization。
但這邊老師有特別提到,應該要對 z1 還是 a1 做 normalization?
答案是實作上影響可能不大,而也要看 activation function 是選擇用什麼來決定,如果跟舉例一樣是 sigmoid 的話,那麼在 z1 做的效果可能會比較好,因為 sigmoid 是一個 s 取線的 function,在0附近的斜率會比較大,因此我們在把 z1 輸入到 sigmoid 之前,就先做 normalization,讓數值縮放到0附近,那麼在計算 gradient 時的數值也就比較大。
但實際上在 hidden layer 很少用 sigmoid,因此實作上在 activation function 之前或之後的 normalization 並沒有太大的差別。

圖4 — 截圖自李宏毅老師課程
Batch Normalization 實際怎麼計算?
我們其實就是將 z 視為一組 vector,然後對它們做上面所說的 normalization,過程都一樣,這邊就不再多解釋了。
然而要計算出 z1, z2, z3 的平均數和標準差,以例子來看是可行的,但當我們的 data 有上百萬筆資料,實作上就不太可行了,因為記憶體會爆掉。
因此 Batch Normalization 就出現了!假設 batch size = 64,那麼我們就只計算這 64 筆資料的平均數和標準差,對它們做 normalization,也因此這種方式適用於 batch size 比較大的訓練方式,因為 batch size 比較大,裡面的資料才比較有可能足以表示整個訓練資料的分佈。
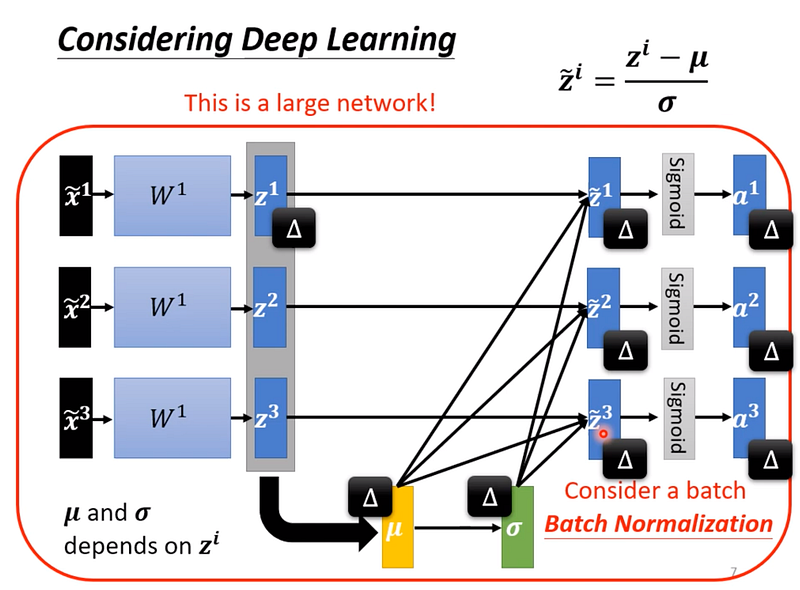
圖5— 截圖自李宏毅老師課程
平均數是0的影響?
當我們對 z 做完 normalization 之後,這組 vector 的平均數會接近於0,而有些人認為這樣會對 network 產生負面的限制,因此在做完 normalization 之後,會再將 z*y + β。
而 z 和 β 這兩個參數,是 network 去學習出來的,是有 gradient 的資訊的,這樣就可以讓 hidden layer 的輸出的平均不會是0。
通常在剛開始訓練時,z 的初始值是1,β是0,目的是為了不要讓做完 normalization 的 vector 的 scale 又變得不一樣,因為這樣就失去做 normalization 的意義。
因此初始值是 z=1, β=0,而到訓練後期,當 loss 走到一個相對平緩的地方,network 可以再加上z, β。
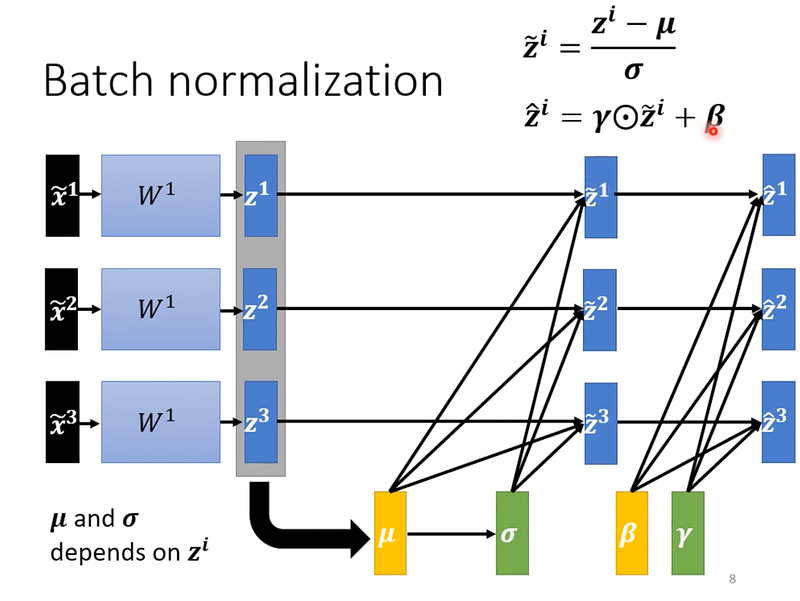
圖6— 截圖自李宏毅老師課程
實驗
這邊拿了之前的論文裡的實驗,來證明 batch normalization 的效果,黑色虛線是沒有用 batch norm 的原始模型(Inception),其餘依序是做了1, 5, 30次的 batch norm,而粉紅色虛線想要表示的是,就算是用 sigmoid 當做 hidden layer 的 activation function,加上 batch norm 後,還是訓練得起來的。(實驗前面有實驗過沒有加入 batch norm,是訓練不起來的)
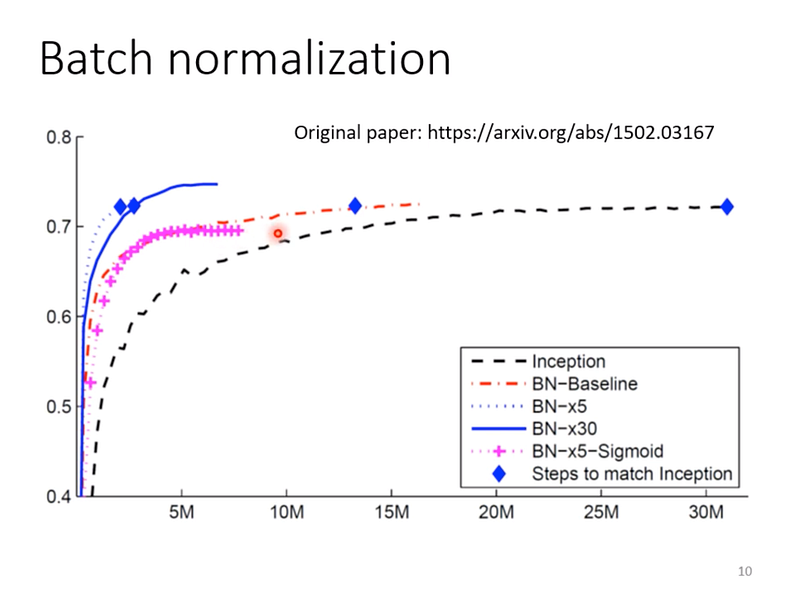
圖7— 截圖自李宏毅老師課程
結語
這堂課雖然短短的半小時,但收穫滿滿,除了了解 batch normalization 的運作方式之外,也很清楚地了解這麼做的原因,以及為何要做 feature normalization。
之後打算做一個簡單的實驗,去比較加入 batch norm 後對於 nn 的差異,期待順利產出了!
以上就是這堂課的筆記了,如果喜歡我的筆記,歡迎給個clap或留下留言!