【李宏毅老師2021系列】自注意力機制 (Self-attention)
【李宏毅老師2021系列】自注意力機制 (Self-attention)
這個系列是在觀看李宏毅老師2021系列的筆記,希望能用更濃縮的方式將內容整理下來。
這次要介紹的是 Self-attention,影片有拆成上下兩集,但因為中間分開的地方有點突兀,所以我還是把筆記合併成一篇文章,有部分內容會省略,有興趣的人可以看影片,內容會更完整。
此篇筆記來自此課程:【機器學習2021】自注意力機制 (Self-attention) (上) 、
【機器學習2021】自注意力機制 (Self-attention) (下)
前情提要
Self-attention 是有名的 Transformer 裡面很重要的架構,影片會先從為什麼需要 self-attention 切入,介紹不同的任務類型,再帶到它的概念、架構與實際的算法。
後半段講解算法的地方,因為用文字不太好表達公式,可以看圖片或許更好理解。
輸入是一堆向量
前幾堂課程的介紹,輸入都是固定形狀的 vector,而輸出可能是一個數值 (Regression),或者一個類別 (Classification)。
但當我們遇到更複雜的問題時 (自然語言),輸入可能會變成一排向量,而且每次輸入的長度不一樣。
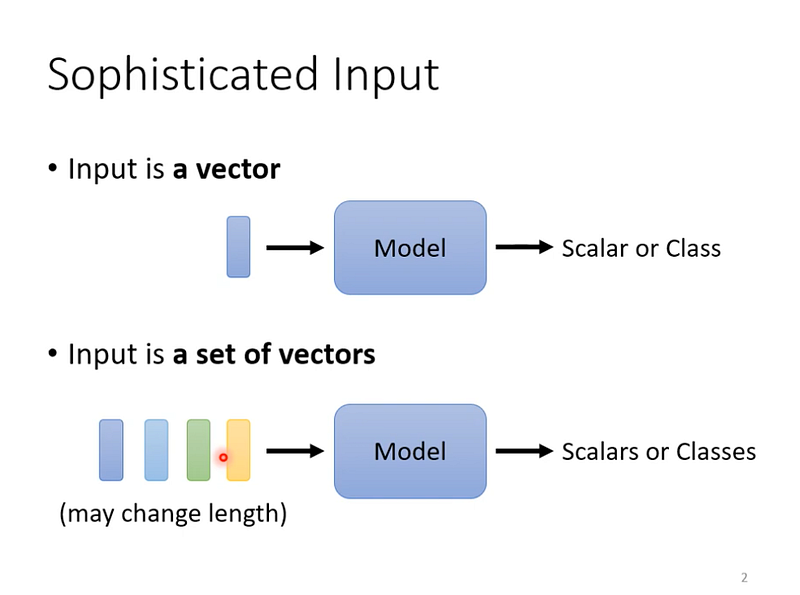
圖1— 截圖自李宏毅老師課程
舉例
文字處理:在做自然語言的任務時,我們需要先將文字轉換成向量 (word embedding),才能輸入到 model 裡面。
每個字串都是一個向量,因此一句話就會變成一排向量。
語音:在語音上會先取一個 window (frame),然後用一個向量去表示某段時間的聲音 (25ms),window 每次往右移動 10ms 直到語音結束。
Graph:一個 socail network 或者分子的結構都是 graph 的形式,每個節點都是一個向量,很多節點就是一堆向量。
輸出的形式
每個向量都會對應到一個 label:Sequence Labeling
- POS tagging:在文字處理上,詞性標註 (POS tagging) 就是這種類別的任務。
- Social network graph:預測每個節點 (使用者) 是否會購買商品,也是這種類別的任務。

圖2— 截圖自李宏毅老師課程
一整個 sequence 只需要產出一個 label
- sentiment analysis:判斷一整句文字是正面負面…等。
- 輸入語音,判斷這句話是誰講的。
- 輸入一個分子 (等於一個 graph),判斷分子的親水性。

圖3 — 截圖自李宏毅老師課程
機器自己決定要輸出多少 label:Seq2Seq

圖4 — 截圖自李宏毅老師課程
以下介紹 self-attention 的例子,都是第一種類型的任務類型。
Fully-connected 的問題
假設是詞性標註的任務,若直接用 fully-connected 來處理,會發現同樣文字在句子的前後,label 是不同的詞性。
I saw a saw,第一個 saw 是動詞,第二個 saw 是名詞,但對 fully-connected 來說這兩個 saw 是完全一樣的。
FC 考慮鄰近的 data
我們可以開一個 window,將鄰近的資料都考慮進來,或是更極端,直接開一個 window 涵蓋所有資料。
這樣的方式也確實會比原本的 fc 來得好,但因為我們的輸入是有長有短的,因此如果真的要開一個 window 涵蓋所有資料,那麼除了運算量很大之外,也容易 overfitting。
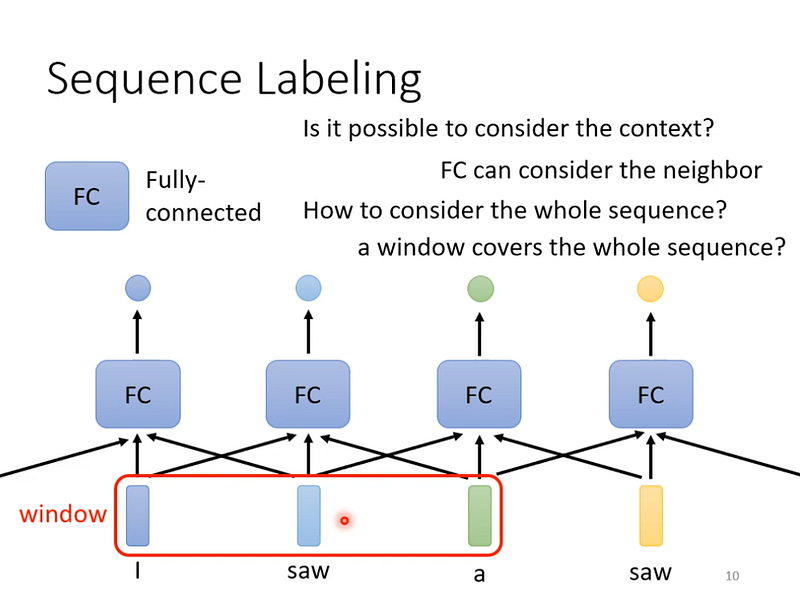
圖5 — 截圖自李宏毅老師課程
Self-Attention
概念
- 以 sequence labeling 的任務為例,輸入4個向量,輸出4個向量。
輸入向量可以是整個模型的輸入,也可以是某層 hidden layer 輸出的向量。 - 每一個輸出的向量,都是考慮過所有輸入向量後才得到的結果。
- 深藍色的輸入,通過 self-attention 後,會得到一個深藍色的輸出,以此類推。
- 接著在把有考慮整個句子的向量,丟到 fully-connected 去輸出我們想要的數值、類別。
- 如此一來,fc 就可以考慮到整組句子的資訊。
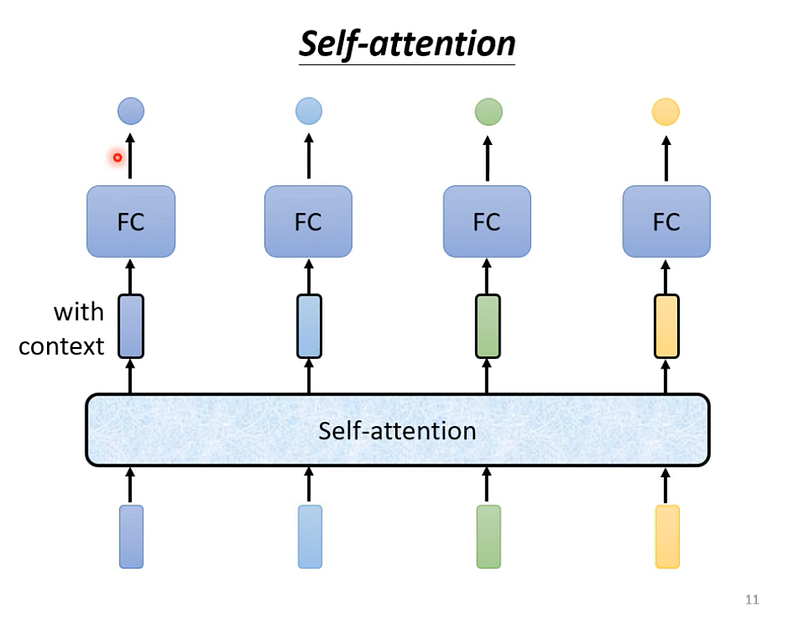
圖6 — 截圖自李宏毅老師課程
self-attention 跟 fully-connected 重疊使用
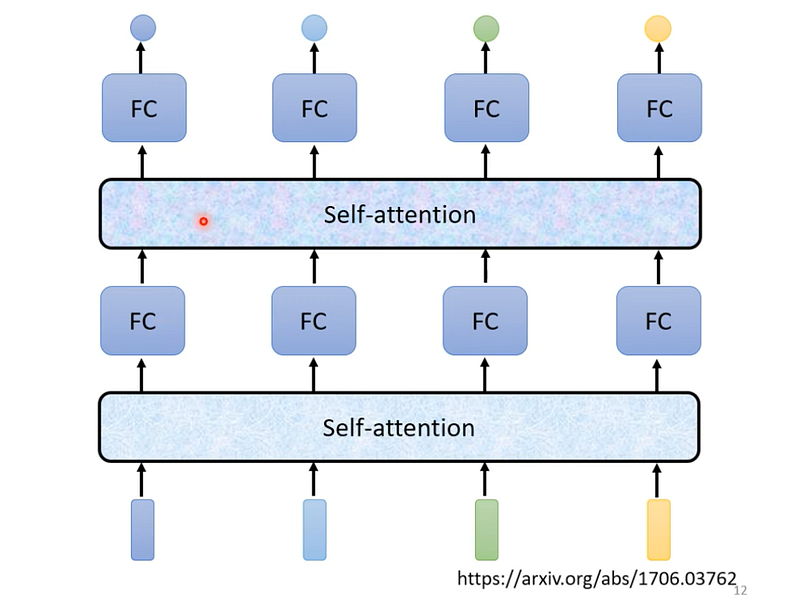
圖7— 截圖自李宏毅老師課程
Attention is all you need
Google 提出 Transformer 的架構,裡面最重要的 module 就是 self-attention (就像變形金剛裡的火種源)
其實在更早的 paper 就有出現過類似的架構,但在這篇文章裡面,才將 self-attention 發揚光大。
Self-Attention 計算方式
Sequence labeling 的輸出 b1 如何產生?
α1:表示輸入的 a1跟其他輸入向量之間的相關性,它會去考慮其他向量裡面,有沒有哪些資訊是 α1 輸出到 b1 會用到的。

圖8 — 截圖自李宏毅老師課程
相關性怎麼計算?
有很多不同種做法,最常見的是 dot product。
Dot Product
假設要計算 a1, a4 的相關性,就會將這兩個向量,分別乘上兩個不同的矩陣(wq, wk),得到 q, k 之後,再對 q, k 做 dot product,得到一個數值(α)。
Additive
同樣乘上兩個不同的矩陣,得到 w, k,但這邊是將它們串起來,過了一個 activation function (tanh),再乘上一個矩陣後,得到一個數值(α)。
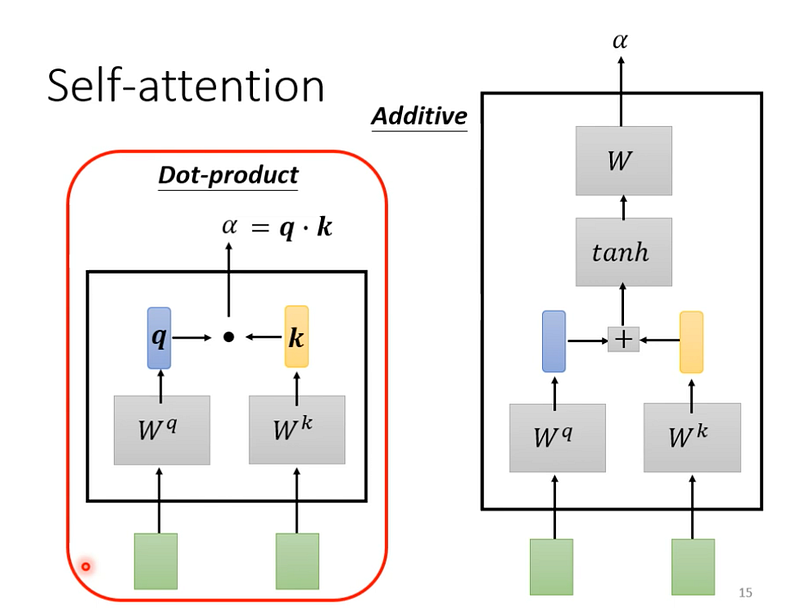
圖9— 截圖自李宏毅老師課程
接下來的解釋都是以 dot product 為主,transformer 也是用這種方式去計算相關性。
Self-Attention 流程
計算 Attention Score
剛剛提到的 q 被稱作 query,k 被稱作 key。
實際要算出 α1 時,需要分別去計算 a1 跟 a2, a3, a4 的相關性。
- 因此我們會將 a1 乘上一個矩陣,得到 q1,a2 乘上一個矩陣,得到 k2,a3, a4 也分別乘上矩陣得出 k3, k4。
- 對 q1, k2 做 dot product 就可以計算出 α1,2,這個數字被稱作 attention score。
- 接著分別對 q1, k3、q1, k4 做一樣的事情,就可以得到 α1,3、α1,4。
實作時也會讓 a1 跟自己做關聯性,因此也會得到一個 α1,1。
這時候我們就有了 α1,1、α1,2、α1,3、α1,4。 - 接著會在過一層 activation function,最常見的是 softmax,但也可以用其他 function 替代。

圖10 — 截圖自李宏毅老師課程
計算 a1 的輸出 b1
根據計算出來的 α,我們已經知道哪些輸入的向量,跟 a1 最有關係,接著要透過 attention score 來抽取 sequence 中重要的資訊。
- 將 a1, a2, a3, a4 乘上一組新的矩陣(Wk),得到 v1, v2, v3, v4。
- 接著將 α1,1 乘上 v1, α1,2 乘上 v2,以此類推,最後加總起來得到 b1。
因此誰的 attention score 比較大,也就是哪個向量跟 a1 的相關性比較大,就更會影響到 b1,而這樣的結果也符合我們的預期。
到這邊就完成了計算輸入一排向量 a1, a2, a3, a4,得到輸出向量 b1 的過程。

圖11— 截圖自李宏毅老師課程
計算 b2, b3, b4
跟計算 b1 的方式一樣,計算過程這邊就略過。
另外實際在運算時,b1, b2, b3, b4 是平行地被計算的。
矩陣乘法的角度
_Query
_在計算每個向量的 query 時,都需要先乘上一個矩陣(Wq)。
q1 = Wq * a1
q2 = Wq * a2,以此類推。
但我們其實可以將 a1, a2, a3, a4 當作一個矩陣(I),這個矩陣乘以 Wq 得到 q1, q2, q3, q4 這個矩陣(Q)。
所以可以寫成 Q = Wq * I。
Wq 就是機器需要學出來的一組參數。
_Key
_K = Wk * I
_Value
_V = Wq * I
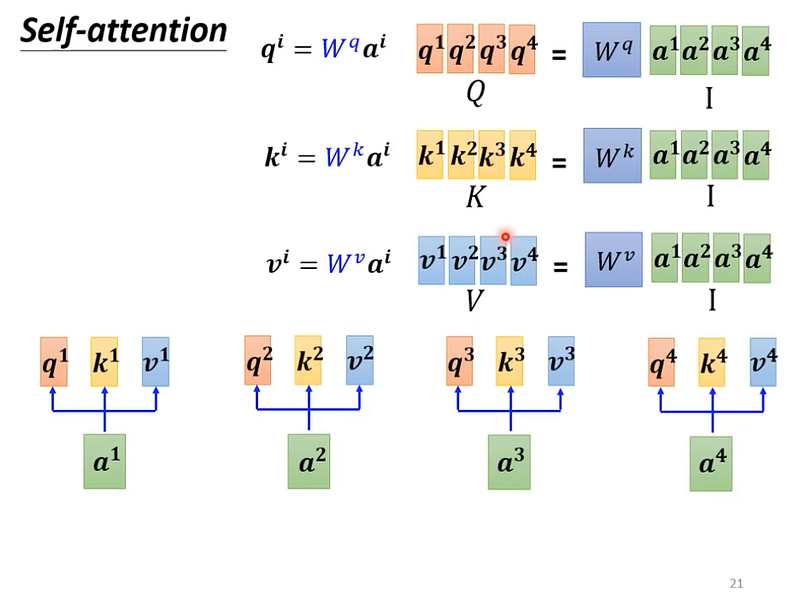
圖12— 截圖自李宏毅老師課程
Attention Score (對 Query, Key 做 dot product)
α1,1= kT * q¹(T 是 tranpose)
α1, 2 = kT * q²,以此類推。
我們其實可以將 k1, k2, k3, k4 當作一個矩陣(k, row 是 k1, k2, k3, k4),乘上 q1 這個向量,而得到 α1 這個矩陣(α1,1, α1,2, α1,3, α1,4),代表著 attention score。
α1 = K * q1
α2 = K * q2
Attention Score 就可以被當作成兩個矩陣的相乘。
A = KT * Q
K 的 row 是 k1, k2, k3, k4,Q 的 column 則是 q1, q2, q3 ,q4。
因為 A 還會通過一個 activation function,所以用 A’ 來代表通過後的輸出。

圖13— 截圖自李宏毅老師課程
self-attention 的輸出:b
我們可以將 v1, v2, v3, v4 是做一個矩陣(V)。
將 V 乘上剛剛算出來的 attention score 的結果(A’)。
就可以得到 B 這個矩陣,它的 column 是 b1, b2, b3, b4。
O = V*A’

圖14 — 截圖自李宏毅老師課程
統整
我們有一堆輸入的向量(I)。
- 計算 Query, Key, Value
輸入向量(I)分別乘以上三種不同的矩陣(Wq, Wk, Wv),得到 Q, K, V(Query, Key, Value)。 - 計算 Attention Score
透過 K 的 transpose 乘上矩陣 Q,得到 A,並且通過 activation function (softmax or others),得到 A’(Attention Matrix)。 - 計算輸出向量(O)
最重將矩陣 V,乘上矩陣 A’,就可以得到輸出矩陣 O。
雖然好像做了很複雜的操作,但其實只有 Wq, Wk, Wk 是需要透過訓練資料找出來的。
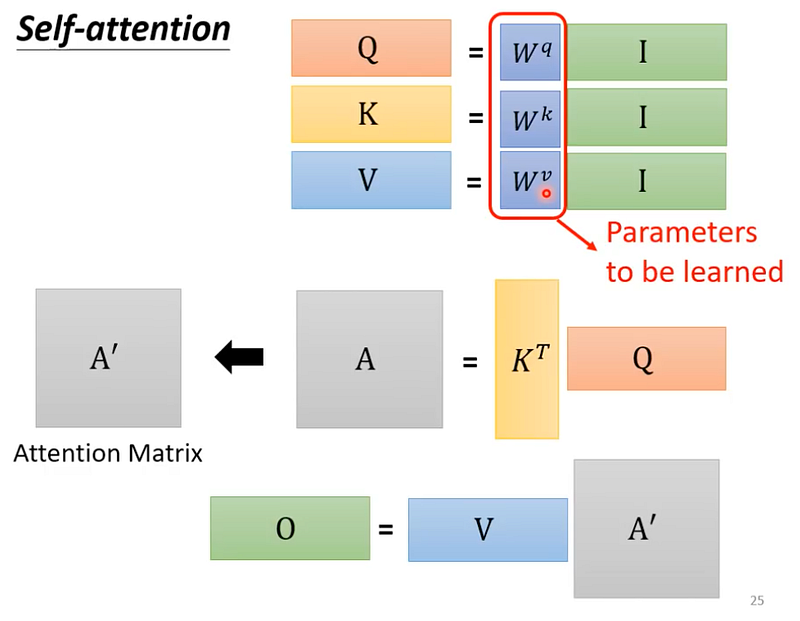
圖15 — 截圖自李宏毅老師課程
變形:Multi-head Self-attention
為什麼要用 multi-head?
相關這件事情可能有很多種形式,可以把它想像成,為了要找到資料中不同種類的相關性,所以才會設定多個 multi-head 的 self-attention。
而需要用多少個 head,是一個 hyperparameter。
在語音辨識、翻譯等任務中,可能會需要用到比較多個 head。
假設 multi-head 設定為2,代表想要找到的相關性的種類有兩個,
因此 query, key, value 這些要學的參數也會有兩種。
影片中有稍微講解算法,但我這邊就先省略。
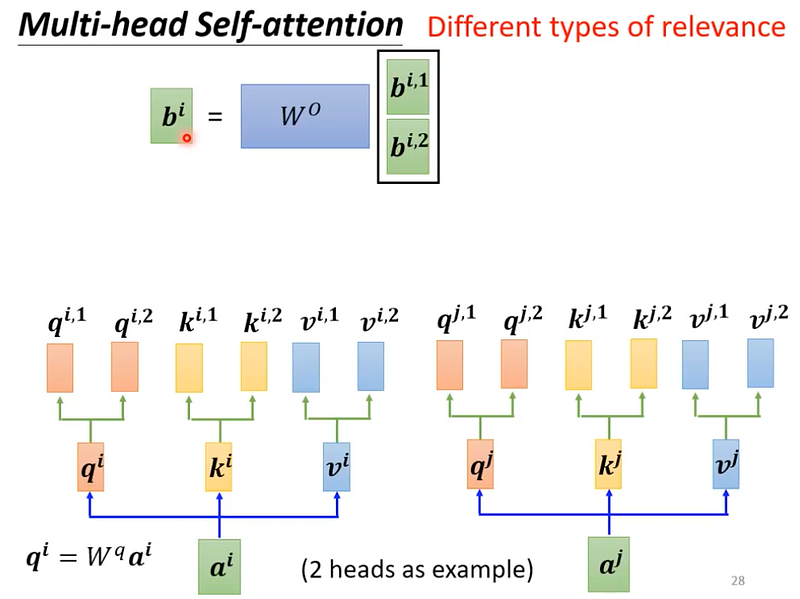
圖16 — 截圖自李宏毅老師課程
Position Encoding
self-attention layer 並不會考慮輸入向量的位置資訊。
對於 layer 來說,當 a1 出現在第一個位置和最後一個位置是一樣的,因為都只是去計算 a1 和其他輸入的相關性。
若要加上位置資訊,可以在 ai 輸入到 self-attention layer 之前,先加上 ei 這個向量,ei 就代表著位置的資訊。
而怎麼產生 ei 向量有很多種方式,可以是統計出來的,也可以是透過機器學出來的,但這些方法都稱作 position encoding。

圖17 — 截圖自李宏毅老師課程
結語
因為將兩個影片的內容放在同一篇文章中,所以後面介紹 multi-head self-attention、position encoding、self-attention 的應用、與 cnn 的比較…等等內容,這邊就都省略掉了。
以上就是這堂課的筆記了,如果喜歡我的筆記,歡迎給個clap或留下留言!